PHP遍历某个目录下面的文件并使用多进程记录到数据库的几种方法比较
{{moment(1482566430000).format('MMM DD, YYYY, h:mm')}}
PHP
PHP
最近工作需要写一个脚本去跑某个目录下面的文件然后记录到数据库,比较了下三种遍历目录的方法.
打印了测试目录weixin下面有多少文件,文件一共3千多,层级深度还是比较深的。

1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68
| <?php * php import.php xxx目录 比如:php import.php images * 此目录是跟脚本同级顶级的目录 */ $t1 = microtime(true); define('BASIC_PATH',P(dirname(__FILE__)).'/'); if(empty($argv)){ exit("请在命令行执行此脚本\n"); } if(count($argv) <= 1 || empty($argv[1])){ exit("请输入需要导入的文件夹,比如php import.php images\n"); } $need_import_dir = BASIC_PATH.$argv[1]; getFiles1($need_import_dir); getFiles2($need_import_dir); $directory = new RecursiveDirectoryIterator($need_import_dir); getFiles3($directory); $t2 = microtime(true); echo '耗时'.round($t2-$t1,3)."秒\n"; function P($path){return str_replace('\\','/',$path);} function getFiles1($dir){ if(!is_dir($dir)){ exit('不是dir'); } $handle = opendir($dir); if($handle){ while(false !== ($file = readdir($handle))){ if($file != '.' && $file != '..'){ $filename = $dir."/".$file; if(is_file($filename)){ echo 'File path = '.$filename."\n"; }else{ getFiles1($filename); } } } closedir($handle); } } function getFiles2($dir){ $directory = new RecursiveDirectoryIterator($dir,RecursiveDirectoryIterator::SKIP_DOTS); $ierator = new RecursiveIteratorIterator($directory,RecursiveIteratorIterator::LEAVES_ONLY); foreach($ierator as $fileinfo){ echo 'File path = ' .$fileinfo->getPathname(). "\n"; } } function getFiles3($dir){ for(;$dir->valid();$dir->next()){ if($dir->isDir() && !$dir->isDot()) { if($dir->haschildren()) { getFiles3($dir->getChildren()); } }elseif($dir->isFile()){ echo 'File path = '.$dir->getPathName()."\n"; } } }
|
法1:测试打印了几次,耗时分别在0.048,0.062,0.078
法2:测试打印了几次,耗时分别在0.092,0.103,0.151,0.065
法3:测试打印了几次,耗时分别在0.037,0.044,0.039,0.045
法2:主要是使用了迭代器RecursiveIteratorIterator,作用是把多维的树形数组转成一维,耗时较多
法1相对法3,传统的不断打开文件句柄也会耗时些
所以建议还是使用法3,关于SPL(PHP标准类库)的了解文章:文章地址
在编码中我们可以多使用SPL标准类库提供给我们的类,告别一些传统的方法,使用一些新的解决方法和思维。
现在已经能够遍历出某个目录下面的所有文件了。如果还想追求速度,可以使用多进程pcntl相关函数来完成。
我其中使用了LimitIterator这个迭代器来控制每个进程的处理的遍历出来文件的偏移,这样子来加快任务处理速度,进程的数量我是通过命令find weixin -type f -print | wc -l查看目录下面的文件个数计算的来设置每个进程处理文件个数偏移的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28
| $directory = new RecursiveDirectoryIterator($need_import_dir,RecursiveDirectoryIterator::SKIP_DOTS); $ierator = new RecursiveIteratorIterator($directory,RecursiveIteratorIterator::LEAVES_ONLY); for ($i = 0; $i < 2; $i++) { $pid = pcntl_fork(); if ($pid == -1) { echo "Could not fork!\n"; exit(1); } if (!$pid) { echo "child process $i running\n"; $offset = $i*1800; $limit_iterator = new LimitIterator($ierator,$offset,1800); foreach($limit_iterator as $file=>$fileinfo){ recordFile($fileinfo->getPathname()); } exit($i); } usleep(1); } while (pcntl_waitpid(0, $status) != -1) { $status = pcntl_wexitstatus($status); echo "Child $status completed\n"; }
|
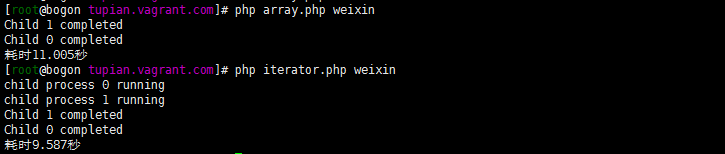
这样子处理速度直接快接近一半了。
也可以不用上面的方法,可以使用法3把所有文件路径跑出来存到一个数组里面,再创建多个进程通过数组偏移来处理。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26
| $directory = new RecursiveDirectoryIterator($need_import_dir,RecursiveDirectoryIterator::SKIP_DOTS); $total_files = getFiles3($directory); $chunk_size = 1800; $chunk_list = array_chunk($total_files,$chunk_size); for ($i = 0; $i < count($chunk_list); $i++) { $pid = pcntl_fork(); if ($pid == -1) { echo "Could not fork!\n"; exit(1); } if (!$pid) { foreach($chunk_list[$i] as $value){ recordFile($value); } exit($i); } usleep(1); } while (pcntl_waitpid(0, $status) != -1) { $status = pcntl_wexitstatus($status); echo "Child $status completed\n"; }
|
经过测试还是第一种通过LimitIterator迭代器偏移开启两个进程更快一些。
——————2016-10-10